Machine Learning - Classification
Publié le 16 novembre 2024
Dans un problème de classification, on prédit une classe en fonction d’une ou plusieurs variables explicatives
Lecture 5 min
Classification
C’est quoi ?
Quand on veux répondre à cette question, on fait de la classification. Dans un problème de classification, on prédit une classe en fonction d’une ou plusieurs variables explicatives
Algorithmes
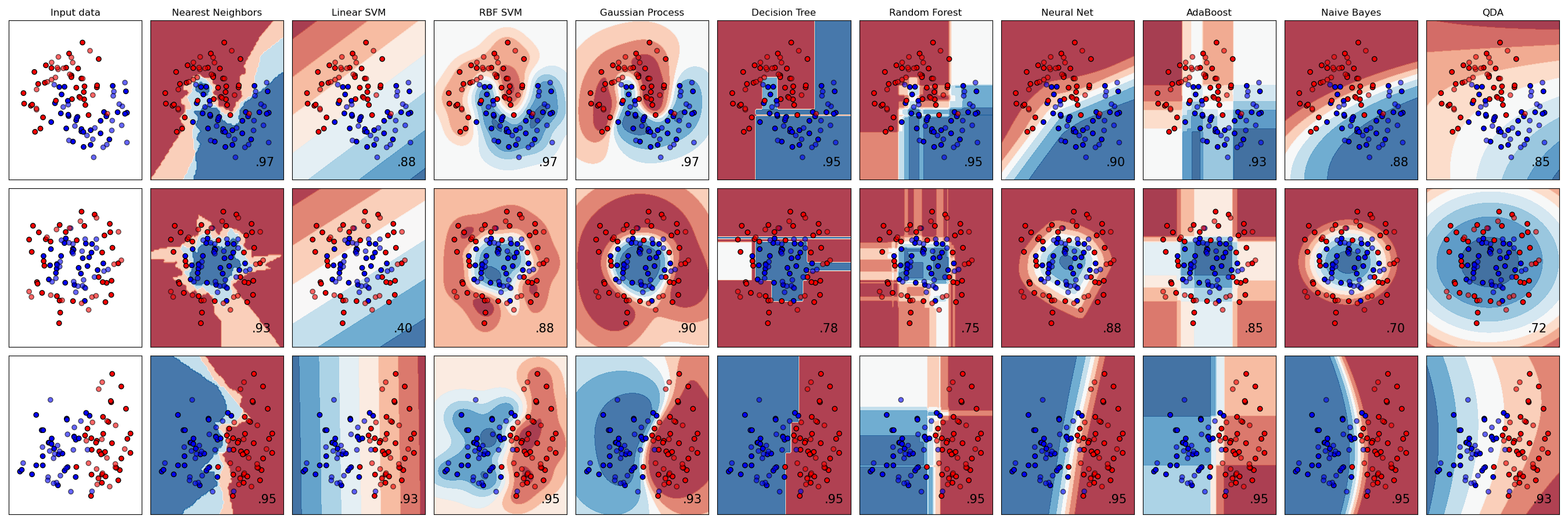
Algorithmes linéaires
Ces algorithmes prennent en compte une relation linéaire entre les variables d’entrée (features) et la sortie (classe).
Exemples :
- Régression Logistique
- Utilise une fonction logistique pour prédire la probabilité d’une classe.
- Fonctionne bien pour des données où les classes sont séparables linéairement.
- Machines à Vecteurs de Support (SVM) avec un noyau linéaire
- Trouve une hyperplane qui sépare les classes dans un espace à plusieurs dimensions.
Avantages
- Simplicité et efficacité pour des données bien séparées.
- Facile à interpréter.
Limites
- Performances limitées sur des problèmes où les classes ne sont pas séparables linéairement.
Algorithmes non-linéaires
Ces algorithmes peuvent capturer des relations complexes et non-linéaires entre les variables.
Exemples :
- K-NN - K-Nearest Neighbors
- Le classifieur k-NN prédit la classe en fonction des classes de K plus proches voisins
- Machines à Vecteurs de Support (SVM) avec noyaux non-linéaires (comme le noyau radial - RBF)
- Permet de séparer les classes dans un espace transformé de dimension supérieure.
Avantages :
- Adaptabilité à des relations complexes.
- Bonne performance pour des données avec des motifs non-linéaires.
Limites :
- Coût computationnel élevé pour de grands ensembles de données.
- Peut être sensible au bruit.
Algorithmes basés sur des arbres
Ces algorithmes utilisent une approche arborescente pour segmenter les données en sous-groupes basés sur des règles de décision.
Exemples :
- Arbres de décision
- Crée une structure hiérarchique où chaque nœud représente une question basée sur les features.
- Random forest
- Combine plusieurs arbres de décision pour améliorer la précision et réduire le sur-apprentissage.
- Gradient Boosting Machines (GBM), XGBoost, LightGBM, CatBoost
- Techniques d’arbres de décision boostés pour améliorer la performance en pondérant les erreurs des prédictions précédentes.
Avantages :
- Flexibles et capables de gérer des relations complexes.
- Peu sensibles aux transformations des données.
Limites :
- Les arbres individuels peuvent sur-apprendre les données.
- Boosting et Random Forest peuvent être coûteux en termes de calcul.
Algorithmes basés sur des probabilités
Ces algorithmes se basent sur des probabilités pour classer les données.
Exemples :
- Naive Bayes
- Suppositions d’indépendance conditionnelle entre les features.
- Modèles de Markov Cachés (HMM)
- Utilisés pour des données séquentielles comme les séries temporelles.
Avantages :
- Rapides et faciles à implémenter.
- Performants sur des ensembles de données avec des distributions simples.
Limites :
- Hypothèses souvent irréalistes (indépendance des features).
- Moins performant pour des relations complexes.
Algorithmes de réseaux de neurones
Ces algorithmes imitent le fonctionnement des neurones biologiques pour apprendre des modèles complexes.
Exemples :
- Perceptron Multicouche (MLP)
- Réseau de neurones classique pour des tâches de classification.
- Réseaux de Neurones Convolutifs (CNN)
- Principalement utilisés pour les données visuelles.
- Réseaux de Neurones Récurrents (RNN)
- Conçus pour les données séquentielles comme le texte ou l’audio.
Avantages :
- Capacité d’apprendre des relations très complexes et non-linéaires.
- Performants pour des tâches complexes comme la vision ou le traitement du langage.
Limites :
- Nécessitent de grands ensembles de données.
- Computationalement coûteux et plus difficiles à interpréter.
Méthodes d’ensemble
Ces méthodes combinent plusieurs modèles pour améliorer la performance et réduire les erreurs.
Exemples :
- Bagging (e.g., Random Forest)
- Combine plusieurs modèles faibles en parallèle.
- Boosting (e.g., XGBoost, AdaBoost)
- Combine plusieurs modèles faibles de manière séquentielle pour corriger les erreurs.
- Stacking
- Combine les prédictions de plusieurs modèles via un méta-modèle.
Avantages :
- Réduction de la variance et du biais.
- Excellente performance sur des ensembles de données variés.
Limites :
- Plus complexes à entraîner et interpréter.
- Coût computationnel élevé.
Étapes
from sklearn.model_selection import train_test_split
from pycaret.classification import setup, compare_models, tune_model, blend_models, plot_model
Création des jeux de données
On filtre le dataset avec les colonnes qui nous intéressent
On découpe en 2 jeux de données
dataset_train, dataset_test = train_test_split(
dataset,
test_size=0.3,
random_state=42,
stratify=dataset['col']
)
stratify garantit que la proportion reste la même après découpage entre le train et le test
Initialisation
exp = setup(
data=df,
target="zone",
session_id=42
)
remove_outliers = True permet de supprimer les valeurs aberrantes
normalize = True permet de placer les variables dans une gamme standardisée et plus facile à exploiter par les algorithmes
Comparaisons
On lance la comparaison des différents algorithmes
model = compare_models(exclude=[])
Optimisations des hyper-paramètres
best_model_tuned = tune_model(model)
Combinaisons de plusieurs modèles
top_5_models = compare_models(n_select=5, exclude=['xgboost', 'catboost'])
blended_model = blend_models(top_5_models)
Métriques
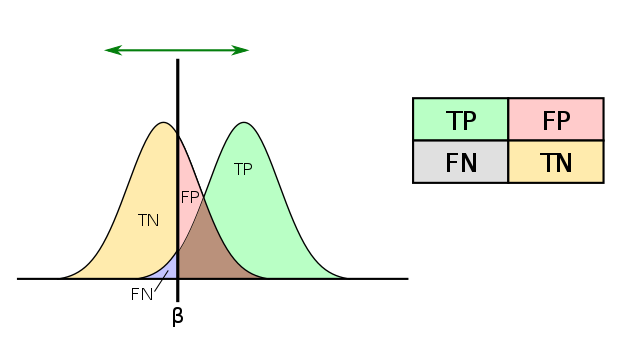
Matrice de confusion
La matrice de confusion répertorie le nombre d’échantillons prédit pour chaque classe possible en fonction de la classe réelle
plot_model(model, plot='confusion_matrix')
Précision
La précision est la proportion de tests retournés positifs à raison parmi l’ensemble des tests retournés positifs
precision = TP / (TP + FP)
Rappel
Le rappel est la proportion de tests qui ont été retourné positifs parmi l’ensemble des tests qui auraient dû être retournés positifs
recall = TP / (TP + FN)
ROC / AUC
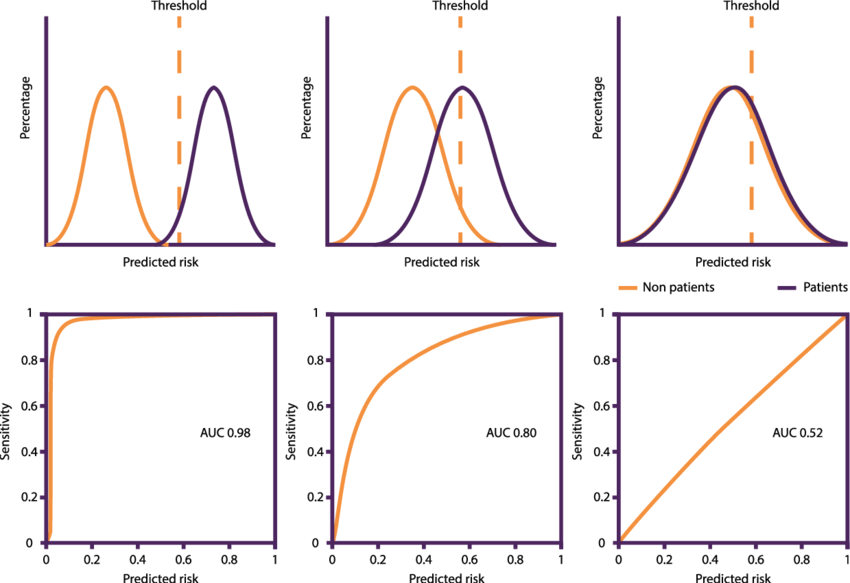 La courbe jaune correspond aux Vrai Négatif, et la bleu Vrai Positif, l’intersection étant le seuil d’erreur possible.
La courbe jaune correspond aux Vrai Négatif, et la bleu Vrai Positif, l’intersection étant le seuil d’erreur possible.
La courbe ROC permet de comparer différents algorithmes en faisant varier leur seuil de détection.
Le modèle avec la plus grand aire sous la courbe est le meilleur modèle.
plot_model(best_model, plot='auc')
Importance des variables explicatives
plot_model(best_model_tuned,'feature')